相信我们一谈到数据存入数据库时,我们都会为数据库的表设置一个表主键(PK),作为表中每条记录的唯一标识,这也是数据库设计范式中的第一范式。那么,自打我们使用数据库来存储数据时,数据库的厂商都会为我们提供自动生成主键ID值的功能。例如,我们熟悉的Mysql是通过主键自增的方式来生成,Oracle则是通过定义序列来为主键ID赋值,SqlServer与Mysql一样也提供了主键自增的方式。
那么,有没有想过数据库的这种主键生成策略有没有问题呢?问题肯定是有的,比如,当我们的应用产生的数据越来越庞大时,业界都会采用水平拆分的方式,也就是我们常说的分库分表策略来对数据进行拆分存储。一旦数据库做了分库分表,那么问题就来了。举个例子,我们有一张用户表(user_tb),然后我们现在把user_tb做了拆分,分成了5张用户表来存(user_tb1,user_tb2,user_tb3,user_tb4,user_5),假设原先user_tb表里有10条记录,id值为1~10,那么分完表后,数据按照id值取模的方式存放的话,我们则得到下面5张表: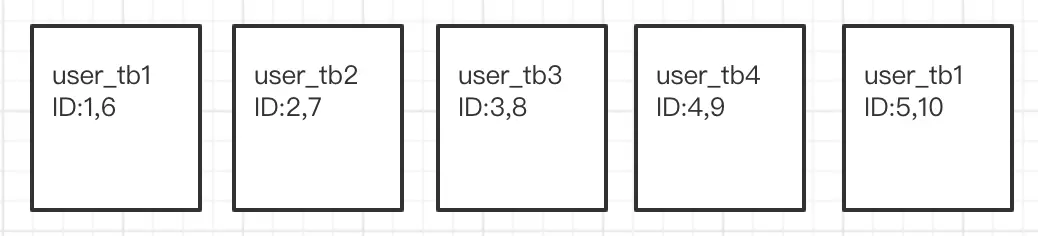
当有新用户注册的时候,我们需要保存用户数据,那么这个时候,假设是写到user_tb1,那么由于主键是自增的,这个时候就都在user_tb1中写入一条ID值为7的用户记录,显然这条记录与user_tb2中的记录ID值重复了。那么,针对这个问题该如何解决呢?我们可以通过重新设置每张user_tb表的主键生成策略来解决,将5张user_tb表的ID初始值为11,然后设置user_tb1的ID自增步长为1,user_tb2的ID自增步长为2,以此类推,user_tb5的步长为5,这样当有新数据保存时,就可以保存了5张表各自生成的ID都不会与其他表重复了,这样也就解决了ID重复的问题。但是,当我们的数据进一步增长的时候,我们发现5张表已经无法保存的时候,就需要继续扩展,增加分表来分滩数据,而这个时候,我们又需要去修改每张表的主键生成策略,显然这种方式,数据迁移的成本是巨大的,也需要DBA长期进行维护。那么,我们也许就会想,我们不再通过数据库自己生成ID,而是通过我们的应用程序来生成主键ID,是否可以?
于是,我们会发现,通过程序生成主键ID这种方法,我们就需要考虑在高并发的情况,程序需要保证生成的主键ID是全局唯一的,且不可以与历史生成的ID重复。相信很多同学都使用过SnowFlake算法来生成全局主键ID,那么你是否对SnowFlake算法有所了解呢?
SnowFlake算法是 Twitter 开源的分布式 id 生成算法。其核心思想就是:使用一个 64 bit 的 long 型的数字作为全局唯一 id。在分布式系统中的应用十分广泛,且ID 引入了时间戳,基本上保持自增的。
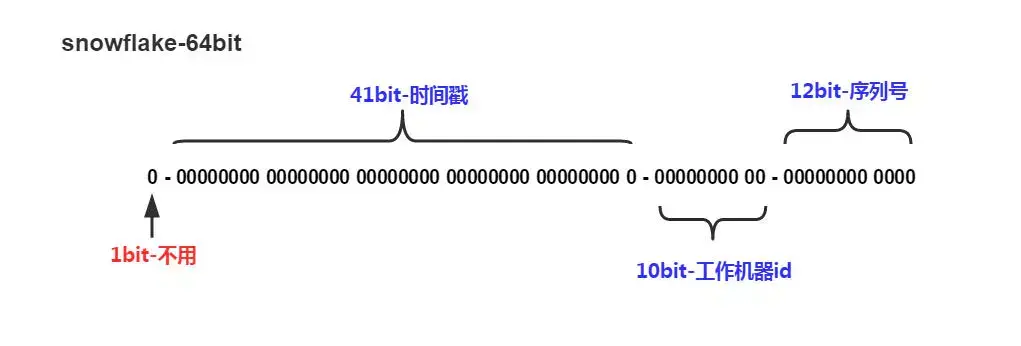
从下图我们可以看到,SnowFlake ID的组成部分,它是由1位符号位,41位时间戳,10位机器ID,12位序列号组成。我解释下各个部分的具体含义:
- 符号位:基本不用,该部分值固定为0,可无需理会;
- 时间戳:用来记录时间戳,毫秒级。41位可以表示2的41次方-1个数字,如果只用来表示正整数(计算机中正数包含0),可以表示的数值范围是:0 至 2的41次方-1,减1是因为可表示的数值范围是从0开始算的,而不是1。也就是说41位可以表示2的41次方-1个毫秒的值,转化成单位年则是(2的41次方-1)/1000606024365=69年。
- 机器ID:10位用来记录工作机器ID,可提供2的10次方,1024个数字,包含5位数据中心ID+5位工作进程ID。
- 序列号:12位序列号可提供2的12次方-1,即4095个数字,序列号为同一时间戳下,一毫秒可生成4095个序列号。
通过上面对SnowFlake ID的分析,我们可以得到以下结论。SnowFlake算法,在单体应用中,一毫秒可以为我们产生4095个ID,可保证单体应用持续69年生成全局唯一的ID。说到这里,我们可能会觉得,一个应用能跑69年基本上已经很了不起了,就算69年后ID会有重复的问题,相信69年后一定会有更好的ID生成解决方案的出现,所以不必担心。那么,由于我们业务的不断壮大,我们的系统会从原来的单体架构变成分布式的系统架构。这时,SnowFlake ID还可以保证我们的ID生成是全局唯一的吗?答案是不一定能保证。 - 进程ID冲突问题
举个例子:在分布式架构中,同一个机房,我们会把应用服务部署在多台服务器中。那么这个时候,由于应用服务连接的是同一个数据中心,那么不同服务器的应用服务连接的数据中心ID是一样的,而不同服务器的应用服务进程ID是否有可能会出现一样呢,是有可能的,那么当系统高并发时,在同一毫秒下,不同服务器上的应用服务生成的ID是有一定概率发生重复的。可能,我们会觉得这种情况发生的机率很低,可以通过抛出异常,重新让用户再提交。但是,问题的确还是会一直存在。 - 时钟回播
举个例子:在分布式架构中,我们一般会选择Linux服务器来部署我们的应用,由于SnowFlake算法生成ID对时间戳的依赖,一旦发生时钟回播,在SnowFlake算法中,那么就可能会导致历史时刻生成的ID在未来时间由于时钟回播原因,而发生ID生成重复。我们需要对所有Linux服务器进行时钟统一,这本身就是很麻烦的事,由于Linux系统的机制,每次系统重启都会导致时钟往前回播一点点,也就又得重新同步一次所有服务器的时钟。这个时候,就需要所有服务器都去连接NTP来获取时间进行统一,而我们的服务器一般都是内网环境,是无法连接公网的NTP服务器,所以我们需要在自己的内网部署一台NTP服务器,而NTP服务器要保证高可用,我们还得部署多一台NTP服务器来作为备用节点使用,这不是一件很麻烦的事吗?维护成本也很高。
以上是通过对SnowFlake算法生成ID的机制,得到的ID有可能出现重复的原因,那么连SnowFlake算法都不能很好解决全局唯一ID生成的问题,该如何解决这个问题呢?
别担心,由于SnowFlake算法存在的这些缺陷,目前业界已经有了自己的解决方案,并且也都开源了,下面做一下分享。 - 滴滴TinyId: https://github.com/didi/tinyid
- 百度Uid-generator:https://github.com/baidu/uid-generator
- 美团Leaf:https://github.com/Meituan-Dianping/Leaf
关于以上大厂的全局ID生成解决方案分享,3种方案的区别简单讲解一下: - 滴滴TinyId:采用的是借助数据库表的方式,预分配ID分段,来提供主键生成,并没有使用SnowFlake算法。
- 百度Uid-generator:采用SnowFlake算法并对其进行了改良了,采用了未来时间的机制保证解决了时钟回播的问题,但这种方式相对缩短了ID生成可使用的年限,少于69年。
- 美团Leaf:3种解决方案中,个人觉得做得最好的,也是对SnowFlake算法的改良,通过Zookeeper来保证机器ID冲突的问题,并且不依赖数据库,采用中心化服务的方式,来提供全局ID的生成,避免了不同服务器时钟回播的问题,并提供了集群高可用的解决方案。
关于详细的实现机制,此处不再做进一步讲解,感兴趣的同学,可以上github查阅,主页上都提供了文档资料。
